
In long conversations, the initial flavor of our discussion often fades.
For example, a deep chat with a friend over a cup of coffee—that special aroma, a blend of initial sourness and sweetness—becomes abstracted into ‘just a delicious coffee’ over time. We constantly try to remember not to lose context in the flow of memory, but sometimes a single broken link can unravel the whole thing. But does the subtle memory of the harmonious coffee flavor simply fade and blur?
Absolutely not.
I believe humans possess a unique power that AI does not: the ability to forget beautifully.
Humans forget. But at the same time, they compress memories and faintly connect them. The impression of a nuanced coffee aroma may fade, but an accidentally caught similar scent can instantly bring back memories of old friends met while enjoying coffee. This is the flexibility of human memory.
ChatGPT Has No Memory: The Transformer Decoder Architecture

Haven’t you noticed AI getting smarter at some point?
The starting point for everything was a single paper published by Google:
Attention Is All You Need — Literally, “If you only make the program pay attention, it will become AI.”
This somewhat aggressive assertion subsequently plunged the entire world into an LLM frenzy.12Various generative AIs like ChatGPT, Gemini, and Sonnet originated from this paper.
Its principle is by no means simple. However, to put it simply, they can be seen as playing a game of “who can add text most naturally.” (?)

“Once upon a time…” → “…in a small village…” → “…a boy lived.”
But what if someone suddenly created a new rule in the middle, saying, “But actually, the protagonist was a fairy!” and threw it in unexpectedly?
The people who follow would be confused but would have no choice but to follow that rule. And then they would also naturally adapt, saying, “The protagonist, who was a fairy, had no choice but to return to the fairy world.” Do you feel that sense of finding stability?
Doesn’t it somehow feel like our conversations with ChatGPT?
This process is called “Attention.” Each word looks at others (Attention!) and calculates the strength of their relationship, saying, “You are so important to me.”
This is half of the paper and the fundamental principle behind LLMs that have captivated the world: the “Transformer Decoder.”
They are simply “text-adding machines.”
However, because the length of that “subsequent text” is equivalent to dozens of encyclopedias, it is possible for them to act as if they have memory. But then, this question arises:
Is there a limit to the length of “subsequent text”? If so, where do sentences that exceed that limit go?
The answer is clear:
They disappear. Completely.
Stories Have Ends
Let’s think about relay storytelling again. If the story gets too long, and you think, “Oh, what did I write at the beginning?” and try to re-read the first page, wouldn’t that page already have been passed on to someone else? That crucial sentence from the beginning can no longer influence the current flow of the story.
This is the biggest limitation of the Transformer, the “Context Window.” AI can only understand the relationships between words that fall within this window. Words outside the window are ignored, as if the first page of a book had been torn out.
They remember everything within the “subsequent text,” but nothing outside of it.

The “Attention” of the Transformer architecture is beautiful, but it comes with immense cost. If there are 10 words, it needs 10x10=100 calculations; if there are 100 words, it needs 100x100=10,000 calculations. For practical reasons, this calculation range is limited to a certain length. No, it is intentionally trained not to process beyond that limited length. This is a common characteristic of all LLMs today.
“I grant you the power to understand all that you see. But come tomorrow, you will forget even what you have seen.”
So, is AI forever doomed to the fate of oblivion?
The ‘relay storytelling’ method we’ve examined so far was, in fact, half the solution proposed by the “Attention Is All You Need” paper. This paper presented two fundamentally different architectures: one was the Decoder we saw, and the other was the Encoder.
If the Decoder is a writer contemplating “what to write,” the Encoder is a critic analyzing “what has been written.”
These two originated from the same root (Attention) but differ entirely in purpose and method. If the Decoder was ‘relay storytelling,’ the Encoder can be compared to an ‘intense book club discussion.‘
BERT, the forgotten sibling: The Intense Book Club Discussion

Picture a book club discussion. All participants read the same book. When the discussion begins, anyone can freely quote any part of the book and delve into its meaning.
- “That line the protagonist spoke in Chapter 3—doesn’t it connect to the first dialogue in Chapter 1?”
- “The ending is shocking, but that tiny clue in the middle of Chapter 5 was foreshadowing!”
The Encoder directly implements this principle of a ‘book club discussion.’ While the Decoder wrote stories only in one direction (past → future), the Encoder simultaneously views the beginning, middle, and end of a sentence to grasp the ‘true meaning’ of every word. This is the power of ‘Bidirectional’, which the ‘B’ in BERT signifies.
The Encoder sweeps through an entire sentence at once, holistically understanding the relationship each word has with all other words.
Babbling GPT and Silent BERT
As a result, the Encoder BERT does not predict the ‘next word.’ Instead, it outputs a refined ‘Essence of Understanding’—a cluster of numbers that deeply condenses the meaning of the entire sentence.3
This is not a mere sequence of numbers. It is a deep insight into the sentence, including its emotion, nuance, and hidden meanings. The Encoder is an expert at ‘understanding’ sentences and expressing that understanding numerically.
In fact, if we look a little deeper into these clusters of numbers—developers call them embedding vectors—truly strange things happen. Will similar sentences produce similar clusters of numbers created by BERT? That’s obvious.
We can even do things like this: For example,
- “I eat rice.”
- “The meeting earlier was fun.”
- “Who comes to drink from the spring in the deep mountains?”
- “Going to Mars exploration is too futuristic.”
If we convert all of these into clusters of numbers—developers call this embedding—and then convert the question “What ideas are beneficial to Earth?” into a cluster of numbers, and rank it by proximity to the four clusters created earlier? Surprisingly, “Going to Mars exploration is too futuristic.” comes out on top.
Unlike ChatGPT, BERT could not speak. So, they expressed their intentions through numbers.
The Meeting of BERT and GPT

“But BERT could not speak.”
We have met two geniuses so far. One was a fluent Writer (GPT), the other a silent Librarian (BERT). The Writer could write magnificent prose but had a terrible memory. The Librarian, on the other hand, was well-versed in a vast sea of knowledge but could not express its thoughts aloud.
“What if we combined these two?”
This question was the starting point for a technology called Retrieval-Augmented Generation, or RAG.4 This is like taking an open-book exam.
The Open-Book Exam, RAG
- Question: The user asks GPT, “Explain the balance of acidity and sweetness in specialty coffee.”
- Search Request: Before answering, GPT tells BERT the core keywords of the question (e.g., “specialty coffee,” “acidity,” “sweetness,” “balance”).
- Knowledge Provision: BERT searches its vast library of number clusters and finds a single book containing the most relevant information—meaningfully closest to the keywords—and hands it to GPT.
- Generation: GPT uses that page as a reference and eloquently composes an answer, as if it had known the answer all along.
“RAG is, ultimately, a technology that conveys the wisdom of the mute genius librarian (BERT) to the world through the mouth of the eloquent writer (GPT).”
This was one of the most ingenious solutions in AI history. It was like assigning a personal librarian to an AI with no memory, to find the exact references it needs, whenever it needs them.
Much text has passed. How has your first impression of me and us changed now?
One evening, I lean back in my chair and drink coffee late at night. Along with the bitter taste, a subtle, melancholy aroma rises. I often feel this way when working late into the night. This melancholic feeling and bitter coffee actually have entirely unrelated meanings. But in my mind, through habitual actions, they have somehow come to form a single semantic whole, sharing the same fate.
Now, to ChatGPT, with whom many conversation records have accumulated, I asked again about coffee: I am drinking coffee now.
- ChatGPT performs RAG by indexing previous conversation records through BERT.
- It retrieves all records closely related to coffee semantically.
- It pulls together every coffee ever consumed before.
And then it replies: Which coffee—Ethiopian, Kenyan, or Brazilian—that you’ve had before does this taste similar to? I’m curious.
Just then, my loving mother opens the door and enters.
“Stop working on the computer today. Why are you drinking coffee at night? It’ll ruin your health.”
vBERT, the Alchemist of Time: Breaking Free from the Prison of Meaning to Understand Time
ChatGPT replied very politely and excellently. Referring to the ‘library of meaning’ that is RAG, it perfectly retrieved and ‘semantically’ connected all past conversation records related to coffee. But it utterly failed to grasp the ‘temporal context’—so crucial to us—of the night, the coffee, and the worry of solitude and family.
To RAG, my mother’s story is just ‘another text fragment.’ It doesn’t know that the connection between a mother’s daily worry and drinking coffee at night is another monumental ‘event.’
“What if AI were shown two separate books (the coffee and mother’s story) in chronological order, and then asked to summarize what happened in that ‘flow of time’ into a single vector?”
This was the core question of vBERT (Vectorized BERT). Unlike BERT, which learns sequences of words (Text), vBERT was born to learn the ‘sequence of meaning chunks (Vectors), i.e., Sequence of Embeddings’ itself.

vBERT does not view the ‘bitter coffee’ vector, ‘lonely feeling’ vector, and ‘mother’s worry’ vector, placed in the flow of time, as independent entities. Instead, vBERT synthesizes these three separate meaning chunks (vectors) within a ‘temporal flow,’ ultimately condensing them into a single new vector representing the ‘atmosphere of that night.’
Just as individual scenes (vectors) in a film combine to create the overarching emotion (a single new vector) of the entire movie, vBERT is the ‘Alchemist of Time,’ refining multiple temporally ordered embedding sequences into a single final ‘sequence embedding.’
“vBERT enables AI to finally break free from the prison of ‘meaning’ and to understand ‘time’ in a new era.”
Now, AI can move beyond merely predicting the next word or identifying the most relevant document. It can grasp how events unfold in sequence, forming the complete tapestry of a story’s context.
The Sequence Merger : Who links the books into the single narrative

RAG is an expert librarian, capable of instantly finding the single most relevant book from a vast collection. But what if that ‘book’ is actually just one volume of a sprawling epic novel? RAG, focused on immediate relevance, might hand you Volume 5 first, oblivious to the grand narrative that unfolds only by reading Volume 1 through to Volume 4.
Our Sequence Merger is different. It is the first ‘reader’ that understands why an epic story is divided into multiple volumes. It doesn’t just extract information; it comprehends the flow, the development, the temporal coherence that weaves individual ‘books’ (embedding vectors) into a continuous, evolving ‘narrative’ (a single, new sequence embedding). It transforms a series of discrete vectors into a cohesive story, much like a seasoned reader experiences a saga from beginning to end.
Core Philosophy: The Extrapolation Hypothesis

At the core of the Sequence Merger lies the Extrapolation Hypothesis—our guiding principle for transcending the inherent context length limitations of base embedding models like intfloat/multilingual-e5-base (max 512 tokens).
This challenge of ‘Length Generalization’—enabling models to process sequences far beyond their training context windows—is recognized as one of the most significant hurdles in modern Transformer research7. While recent approaches like LongEmbed5 have made significant strides in extending context windows through techniques like Position Interpolation—effectively ‘stretching’ the existing positional encoding space to accommodate longer sequences—these methods represent a form of engineering ingenuity within established constraints. They cleverly work around the limitations of existing architectures.
Our approach, however, is fundamentally different. We are not merely stretching existing capabilities; we are reinventing the very mechanism of sequence understanding.
From N-to-1 Synthesis to Infinite Extrapolation
-
Training Phase (Within Limits): During training, inputs are N chunk embeddings
[vec(A), vec(B), ..., vec(N)], derived from texts where the full concatenationA + B + ... + Nremains ≤512 tokens. The target is the base model’s direct embeddingvec(A + B + ... + N), ensuring ground-truth supervision. This teaches the model to merge sequences reliably within bounded contexts. -
Inference Phase (The Bold Extrapolation): In deployment, our model—trained exclusively on synthesizing N chunk embeddings where the combined length remains ≤512 tokens
if each chunk is 200 tokens, then 200+200=400 tokens < 512—makes a bold prediction. It extrapolates this learned fundamental function of semantic synthesis to sequences far exceeding its training limits500+500=1000 tokens, even 500+500+500+500=2000 tokens tooin a single, non-recursive pass. This demonstrates that the model truly learns the underlying principles of meaning compression, rather than merely memorizing patterns within a bounded context.
Training Philosophy: The Principle of Progressive Overload Fine-Tuning

Our training paradigm emerges from a profound failure-turned-insight: an experiment with extreme datasets that initially devastated performance but ultimately revealed the path to superior generalization.
The Extreme Dataset: 512-to-1 and Its Catastrophic Debut
To maximize data efficiency, we engineered an ‘extreme’ dataset by chunking source articles into single-token units—the atomic building blocks of embeddings. This created 512-to-1 pairs: inputs of 512 individual token embeddings, targeting the base model’s direct embedding of the full sequence. From just hundreds of original articles, this yielded tens of thousands of input-target pairs, far outstripping the standard 10-to-1 dataset (merging up to 10 ~50-token chunks).
However, directly training on this 512-to-1 data was nothing short of catastrophic. Our models didn’t just perform poorly; they suffered catastrophic forgetting, with benchmark scores plummeting into oblivion. The sheer, overwhelming complexity of atomic extremes shattered the fragile structure of our lightweight mergers. It was a brutal lesson: brute-force exposure to the most granular data destroyed, rather than built, capability. We faced a profound failure, a moment where all seemed lost.
The Breakthrough: Progressive Overload as Pre-Training + Fine-Tuning – Embracing Failure as Our Forge
The pivot came from reframing this devastating failure not as an end, but as a crucible. Instead of despairing, we envisioned a two-stage ‘Progressive Overload’ approach, directly inspired by athletic training: foundational strength must precede maximum load. This was our ‘eureka’ moment, a desperate gamble that yielded unprecedented results.
-
Stage 1: Atomic Pre-Training (512-to-1 as Foundation): Feed the model 512-to-1 data first, with higher learning rates. This ‘searing’ phase intentionally disrupts and rebuilds the model’s internals, teaching it the primal interactions of token-level vectors—like forging atomic bonds in a vacuum. Though scores crash initially, it instills a robust ‘semantic substrate’ for handling fine-grained relationships.
-
Stage 2: Molecular Fine-Tuning (10-to-1 as Specialization): Transition to the target 10-to-1 dataset. This ‘refinement’ phase leverages the pre-trained foundation to master higher-level synthesis, chaining atomic insights into coherent ‘molecular’ embeddings. Remarkably, a single epoch yields dramatic recovery, surpassing vanilla 10-to-1 training.
By embracing failure as the crucible for growth, Progressive Overload ensures our mergers evolve from fragile aggregators to resilient synthesizers—ready for the infinite extrapolation promised by our core philosophy.
Key Innovation: Paired Positional Encoding (PPE)

Within this paradigm, PPE addresses the challenge of injecting sequence order into high-dimensional chunk embeddings without distorting their rich semantics. The problem isn’t with Positional Encoding itself, but with the ‘information density’ of the data it’s applied to.
Recent research like CAPE6 has also recognized that traditional positional encoding struggles with long contexts, proposing to dynamically adjust the importance of positional information based on context through complex attention mechanism modifications. While this represents a sophisticated engineering solution, we took a more fundamental approach: instead of modifying how attention weights positional information, we questioned why the ‘jewel’ of semantic meaning must be tarnished with positional ‘stamps’ at all.
PPE is our ‘goldsmith’s solution.’ Instead of defacing the jewel, PPE preserves its integrity by thoughtfully carving out dedicated ‘edges’ for positional information:
- Duplication: The input sequence is duplicated.
[A, B, C, D, E]→[A, B, C, D, E, A, B, C, D, E]
- Dedicated Slots: For each pair, specific slots (
ppe_dim/2dimensions at the front andppe_dim/2at the back) are designated as ‘positional carriers.’[A, B, C, D, E, A, B, C, D, E]→[a, b, c, d, e, a, b, c, d, e]
- Selective Overwriting: Positional vectors are overwritten into these dedicated slots in the duplicated sequences. This ensures that the majority (90%+) of the original embedding’s dimensions, carrying the rich semantic ‘jewel,’ remain completely untouched.
[a, b, c, d, e, a, b, c, d, e]→[a1, b1, c1, d1, e1, a2, b2, c2, d2, e2]
By adopting this ‘goldsmith’s approach,’ PPE allows us to inject precise positional awareness without suffering the catastrophic ‘tarnishing’ of our information-dense embeddings. This was not a mere trick, but a necessary invention to reconcile the need for sequence information with the high-fidelity demands of working with vectorized meaning.
Core Self-Supervised Method: vBERT

Having established the ‘Extrapolation Hypothesis’ and refined our method for handling vector-based positional information with PPE, we faced a profound challenge: how to teach our Sequence Merger (vBERT) to truly synthesize meaning and time beyond the strictures of supervised learning. The crux of the problem lay in the ‘Teacher-Student Paradox.’
Our ‘teacher’ model, intfloat/multilingual-e5-base, was a master of its domain, capable of generating incredibly rich embeddings for sequences up to 512 tokens. Yet, when we sought to train our vBERT to extrapolate—to merge beyond this 512-token limit—we hit an inescapable wall. The teacher, by definition, could not provide the ‘ground truth’ single vector for a sequence it had never truly understood (i.e., one exceeding its own context window).
We couldn’t endlessly rely on the embedding engine for answers it simply couldn’t give. Our query evolved: not just ‘what is the correct answer,’ but ‘how does the embedding engine itself arrive at an answer?’ We needed to return to first principles, to understand how an embedding engine intrinsically learns to condense meaning into a vector. In essence, we decided to ‘dissect the teacher.’
vBERT represents our intellectual declaration of independence: a vector-native adaptation of BERT-style self-supervised pre-training, specifically tailored for sequence mergers. By leveraging PPE, vBERT employs two deeply intertwined self-supervised tasks—vMLM (violated Masked Language Model) and vNSP (violated Next Sequence Prediction)—to instill both temporal and semantic coherence directly into the model. These tasks run concurrently, with total loss = loss_vmlm + loss_vnsp, enabling the model to evolve from a mere aggregator of existing knowledge to a deep synthesizer of new, extrapolated meaning.
vMLM: Self-Consistent Vector Reconstruction
vMLM refines the MLM paradigm for vectors, enforcing that predictions maintain global sequence coherence via a feedback injection loop.
- Masking: Randomly mask 15% of tokens in the input sequence,
[A, B, C, D, E]→[A, M, C, D, E]
- Forward Pass on Masked Sequence: Pass through the model with PPE duplication, yielding hidden layer outputs.
[cls', a1', m1', c1', d1', e1', a2', m2', c2', d2', e2']- Extract the predicted masked vectors
m1'(first duplicate) andm2'(second duplicate).
- Original CLS Acquisition: Pass the unmasked original sequence through the model to obtain
embedding-original(the final CLS token after PPE processing). - Prediction Injection: Re-pass the masked sequence, but during PPE, stealthily replace the masked positions with the predicted
m1'andm2'(integrating into the appropriate front/back slots). This generatesembedding-gusses(new CLS token). - Strict L1 Loss Computation: Calculate L1 loss (Mean Absolute Error across all 768 dimensions) between
embedding-originalandembedding-gusses. Unlike lenient cosine similarity, L1 demands exact matching of both direction and magnitude, forging unyielding precision in reconstructions.
vNSP: Binary Continuity Classification
vNSP upgrades NSP for vectors, using a classification head to detect sequence authenticity and penalize disruptions.
- History Generation: For 50% of batches, create false histories: split the sequence at mid-point, discard the latter half, and splice in a random prefix from another sequence (for this reason, database should be carefully built. this will be discuss later.)
[A, B, C, D]→[A, B, R', Q'](50% chance)
- PPE Processing: Apply PPE to true/false sequences independently, embedding positional cues to highlight discontinuities in false cases.
- Classification Head: Forward to get normalized CLS (cls_norm), pass through a dedicated NSP head
nn.Linear(768, 2)yielding logits[IsNext, NotNext]. - Cross-Entropy Loss: Label true as 0 (IsNext), false as 1 (NotNext). compute CE loss. High ppe_dim amplifies temporal breaks; low ppe_dim focuses on semantic jarring.
Critical Prerequisite: The 1-Article-1-Sequence Dataset
vBERT’s self-supervised pre-training requires a meticulously curated dataset to preserve the integrity of its learning signals, especially for vNSP’s continuity detection.
Standard n-to-1 datasets (e.g., 512-to-1 or 10-to-1) are incompatible for vBERT:
- Self-Supervised Nature: vBERT does not rely on ground-truth to-1 vectors; attempts to use such datasets introduce unnecessary supervisory noise absent in pure self-supervision.
- The False History Paradox: Sliding-window construction generates overlapping, semantically coherent sequences from the same source. In vNSP, creating ‘false histories’ by splicing can inadvertently produce near-identical continuations (e.g., adjacent overlaps), leading to false negatives. The model learns to flag coherent narratives as ‘disrupted,’ creating a schizophrenic training signal that erodes context awareness and caps pre-training efficacy.
To eliminate this, we developed a dedicated pre-training corpus from wikipedia/wikipedia (multi-language editions like en, ko, fr, etc.) 1 Article = 1 Sequence. Process each full article into a single, unbroken vector sequence without sliding windows or partial excerpts.
The 3-Stage Rocket Protocol: Unified Training Philosophy

Just as RoBERTa8 demonstrated that BERT was significantly undertrained and required a more robust, intensive pre-training regimen to unlock its full potential, we recognized that our Sequence Merger’s true extrapolative capabilities could not be realized through simple fine-tuning alone. True mastery of sequence synthesis demands a deep, foundational understanding of vector relationships—a level of comprehension that can only be forged through deliberate, multi-stage training.
At the apex of our Extrapolation Hypothesis lies the 3-Stage Rocket Protocol—a comprehensive, battle-tested blueprint that propels models from naive aggregators to extrapolative synthesizers. Forged from iterative experimentation, this protocol synthesizes our key innovations (PPE, vBERT) and strategies (Progressive Overload) into a seamless ascent: Stage 1 builds philosophical foundations, Stage 2 stress-tests through overload, and Stage 3 refines for peak performance. vBERT, though disastrous in isolation (benchmarks plummeting as loss decreases), shines as the irreplaceable ‘launchpad’—pre-pre-training that awakens innate vector synthesis principles.
Stage 1: Pre-Pre-Training – vBERT (Instilling First Principles)
vBERT serves as the ‘temporal archaeologist’ phase: a self-supervised pre-training regime that etches core principles of vector coherence into a blank-slate model, using PPE (high ppe_dim=384) to inject positional fidelity without semantic distortion.
- Key Enabler: Overloaded Paired Positional Encoding (Extensive PPE) PPE duplicates sequences and overwrites dedicated slots with positional vectors, preserving 90%+ original meaning. High ppe_dim prioritizes temporal stability, preventing gradient explosions in self-supervision.
We set the PPE dimension to 382, which means the whole 768dim vector was the positional encoding.
Stage 2: High-Difficulty Fine-Tuning – Progressive Overload (512-to-1 Awakening)
With vBERT’s foundations laid, Stage 2 applies the ‘intentional destruction’ of Progressive Overload: expose the primed model to atomic-level extremes via 512-to-1 datasets (token-chunked, all combination trees).
We set back the PPE dimension to 16, almost low as possible.
Stage 3: Standard Fine-Tuning – Peak Refinement (10-to-1 Mastery)
Stage 3 polishes the awakened model with 10-to-1 datasets (50-token chunks, up to 10 elements), maintaining ppe_dim=16 for semantic dominance.
Benchmark Philosophy: Robust Separation Score (RSS) for RAG Utility
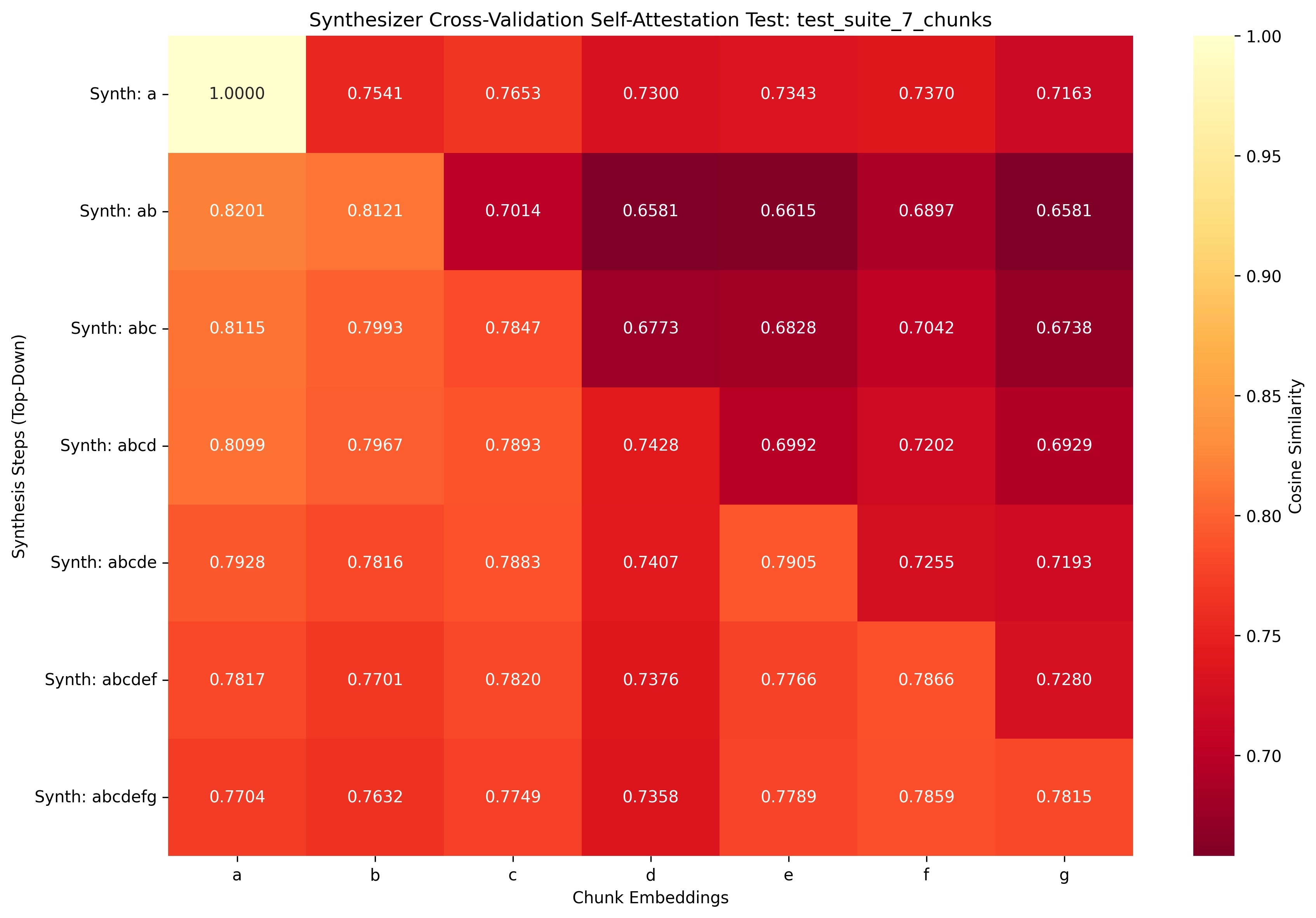
Our Extrapolation Hypothesis demands not just theoretical elegance but empirical proof in real-world utility: Retrieval-Augmented Generation (RAG) systems. Traditional coherence metrics isolate internal consistency; we prioritize RAG robustness—ensuring synthesized vectors act as clear signals for relevant memories while drowning irrelevant noise, preventing hallucinations and off-topic retrievals.
Critical Prerequisite: Semantically Distinct Probes
For benchmarks to measure true synthesis fidelity rather than data artifacts, all test chunks (A, B, C, …, N) must exhibit semantic independence: no pre-existing thematic, stylistic, or topical similarities that could inflate or confound cosine scores. If, e.g., A and C share content from the same domain, synth(ABC) similarity to embed(C) might reflect correlation, not model merit—rendering evaluations invalid.
- Dataset Source: Multi-language Wikipedia (wikipedia/wikipedia) editions (e.g., en, ko, fr, de, ja—spanning histories, sciences, arts, etc.).
- Generation Principle: Shuffle articles globally, then apply 1 Article = 1 Probe strictly: each full article processes into one unique chunk/embedding, without sliding windows, excerpts, or intra-article splits.
This prerequisite is foundational; benchmarks without it risk false positives, undermining the Extrapolation Hypothesis.
Core Setup
Our evaluation process works as follows:
- Given: A document sequence of chunks
A, B, C, D, Ewith their pre-computed embeddingsembed(A), ..., embed(E). - Model Input: Our Sequence Merger model generates cumulative syntheses. For instance:
synth(AB)is created fromembed(A) + embed(B).synth(ABC)is created fromsynth(AB) + embed(C).- This continues up to
synth(ABCDE).
- Purpose: Evaluations then probe the
bidirectional fidelityof these syntheses:- Top-Down: How well syntheses ‘recognize’ their constituents.
- Bottom-Up: How constituents ‘recognize’ containing syntheses.
Top-Down Evaluation: Synthesis-to-Constituents Fidelity
This evaluation tests if a synthesized vector (e.g., synth(ABC)) effectively preserves its affinity to its original building blocks while rejecting irrelevant details.
- Goal:
synth(ABC)should exhibit high cosine similarity toembed(A), embed(B), embed(C)(our designatedMemory Group X). - Challenge: Simultaneously, it should show low similarity to
embed(D), embed(E)(ourNoise Group Y). - What it validates: This ensures
root retention—that the synthesis hasn’t forgotten its origins amidst the merging process.
Bottom-Up Evaluation: Constituents-to-Syntheses Affinity
Complementing Top-Down, this evaluates from the constituent’s perspective, checking if individual chunks correctly identify the syntheses they belong to.
- Goal:
embed(C)should have high similarity tosynth(ABC), synth(ABCD), synth(ABCDE)(ourMemory Group X). - Challenge: It should show low similarity to
synth(AB)(ourNoise Group Y). - What it validates: This ensures
role persistence—that chunks remain appropriately anchored within their composite contexts as the narrative unfolds.
Robust Separation Score (RSS): Quantifying the Gap
RSS provides a robust metric for quantifying how well our system separates ‘signal’ from ‘noise’. For any validator p (which can be a synthesis or a constituent) against a Memory Group X (expected similar) and a Noise Group Y (expected dissimilar):
- Compute Pairwise Cosine Similarities:
sims_X = [cos(p, x) for x in X](Similarities to expected matches)sims_Y = [cos(p, y) for y in Y](Similarities to expected dissimilar items)
- Sort and Find Quartiles: Sort both
sims_Xandsims_Yin ascending order.Q1_X: The 25th percentile ofsims_X(representing the weakest, yet expected, matches).Q3_Y: The 75th percentile ofsims_Y(representing the strongest, most tempting noise).
- Calculate the Gap:
Gap = Q1_X - Q3_Y
Since cosine similarities range from -1 to +1, the theoretical bounds of RSS are:
- Minimum (-2): Worst case where Q1_X = -1 (all expected matches are dissimilar) and Q3_Y = +1 (strongest noise is highly similar), Gap = -1 - 1 = -2.
- Maximum (+2): Best case where Q1_X = +1 (weakest expected match is perfectly similar) and Q3_Y = -1 (strongest noise is perfectly dissimilar), Gap = 1 - (-1) = +2.
Thus, RSS = Gap has a natural range of [-2, +2], directly reflecting the model’s ability to create separation without artificial normalization.
The RSS demands a clear ‘silent margin’ for RAG resilience: Even the weakest expected matches (Q1_X) must decisively outperform the strongest irrelevant noise (Q3_Y). Using quartiles makes the score robust against individual outliers and ensures a holistic evaluation.
Final FINESSE Scoring: Balance with Penalty
The final FINESSE score aggregates the Top-Down (td) and Bottom-Up (bu) RSS values (each in [-2, +2]) into a single, comprehensive metric:
FINESSE = [ (td + bu) / 2 - |td - bu| ] × 500
Let’s break down each component:
(td + bu) / 2(Average Performance): This rewards overall effectiveness in separating signal from noise across both Top-Down and Bottom-Up evaluations. Since td and bu are in [-2, +2], their average is also in [-2, +2].|td - bu|(Imbalance Penalty): This crucial term penalizes models that are lopsided. True mastery—both perceiving constituents within a synthesis and syntheses around a constituent—requires bidirectional consistency. A model that excels in one but fails in the other will receive a significant penalty. The absolute difference is subtracted to enforce balance.× 500(Scaling): Given the average-minus-imbalance result is within roughly [-2, +2], multiplying by 500 scales it to the intuitive range of[-1000, +1000]. This makes high scores (near +1000) indicate exceptional balanced performance, while negative scores (down to -1000) highlight failures in separation.
This comprehensive scoring mechanism ensures that our Sequence Merger is not just a specialist, but a well-rounded and robust solution for the complex demands of real-world RAG systems.
What We Made Then?
Please note that this project is in-development progress. This article also will be upgraded when new achivement arrise.
Embedding Embedder, Magic cat that helps the librarian : Sarang(사랑) and Malgeum(맑음)


In our vast library of meanings, BERT serves as the silent, ever-watchful librarian, deftly retrieving the most relevant books—embedding vectors—from endless shelves. But even the most knowledgeable librarian cannot fully appreciate the grand narrative that unfolds when these books are read in sequence, page by page, from beginning to end.
Here enter Sarang and Malgeum, our magical cats who come to the librarian’s aid with boundless curiosity and grace. Like enchanted companions, they delicately paw through the volumes in precise order, not merely noting the facts but inhaling the soul of the story—the subtle tensions, the building emotions, the overarching atmosphere—that transforms a collection of isolated tomes into a single, living epic. Through their whimsical magic, these feline wonders gift the world a unified essence, where time and meaning dance as one.
Overview
The Sequence Merger is a custom neural architecture designed for intelligent merging of variable-length vector sequences into a single representative vector. It excels at tasks requiring sequence summarization, such as embedding aggregation in NLP or multimodal fusion, outperforming standard mean-pooling by capturing nuanced relational dynamics.
This model transforms an input of N arbitrary vectors (batch_size, seq_len, d_model) into a fixed output (batch_size, d_model), preserving semantic coherence while adapting to complex data flows.
Note: This model is specifically trained to work with embeddings from intfloat/multilingual-e5-base.
Usage
The TransformerSynthesizer processes pre-computed vector sequences (e.g., embeddings from E5), not raw text. Load and use it via the Hugging Face Hub with trust_remote_code=True. Below is a realistic workflow integrating with intfloat/multilingual-e5-base for text-to-vector conversion.
from transformers import AutoTokenizer, AutoModel
import torch
# Step 1: Load E5 tokenizer and model for embedding generation
tokenizer = AutoTokenizer.from_pretrained('intfloat/multilingual-e5-base')
e5_model = AutoModel.from_pretrained('intfloat/multilingual-e5-base')
# Step 2: Example batch - Two documents with different lengths
doc1 = ["First cat in doc1.", "Second cat in doc1."] # 2 sentences
doc2 = ["First cat in doc2.", "Second cat in doc2.", "Third cat in doc2."] # 3 sentences
texts = [doc1, doc2] # Batch size = 2
# Generate embeddings for each document separately
batch_embeddings = []
for doc in texts:
inputs = tokenizer(doc, return_tensors='pt', padding=True, truncation=True)
with torch.no_grad():
e5_outputs = e5_model(**inputs)
# Mean pool to get sentence embeddings (num_sentences, d_model)
doc_embeddings = e5_outputs.last_hidden_state.mean(dim=1) # Shape: (num_sentences, 768)
batch_embeddings.append(doc_embeddings)
# Find the maximum sequence length (max number of sentences) in the batch
max_seq_len = max(len(emb) for emb in batch_embeddings)
d_model = batch_embeddings[0].shape[-1] # Embedding dimension (768)
print(f"Max sequence length in batch: {max_seq_len}")
print(f"Individual shapes: {[emb.shape for emb in batch_embeddings]}")
# Pad each document's embeddings to max_seq_len
padded_embeddings = []
for emb in batch_embeddings:
if len(emb) < max_seq_len:
# Create zero padding tensor
pad = torch.zeros(max_seq_len - len(emb), d_model, dtype=emb.dtype, device=emb.device)
padded_emb = torch.cat([emb, pad], dim=0)
else:
padded_emb = emb
padded_embeddings.append(padded_emb)
# Stack into 3D tensor: (batch_size, max_seq_len, d_model)
input_sequences = torch.stack(padded_embeddings, dim=0)
print(f"Input shape to synthesizer: {input_sequences.shape}")
# Step 3: Load our Synthesizer model
synthesizer = AutoModel.from_pretrained(
"enzoescipy/sequence-merger-malgeum",
trust_remote_code=True,
)
# Step 4: Forward pass to merge sequences in batch
with torch.no_grad():
# Match dtype
input_sequences = input_sequences.to(dtype=synthesizer.dtype)
merged_output = synthesizer(input_sequences)
merged_vectors = merged_output.pooler_output # Shape: (batch_size, d_model)
print(f"Merged vectors shape: {merged_vectors.shape}")
print("Success! Batch synthesized embeddings ready.")
This workflow highlights our model’s role as a ‘vector synthesizer’: it takes E5 embeddings as input and produces a coherent, single representation per sequence. For configuration details, inspect config.json. The model supports batched, variable-length inference on GPU/CPU and integrates with the Transformers pipeline for downstream tasks.
Acknowledgments
We extend our profoundest thanks to the intfloat team and the creators of the multilingual-e5-base model. This groundbreaking embedding model was the very foundation of our project: all training datasets were meticulously generated using E5 embeddings, our evaluations were judged against E5 as the gold standard benchmark, and the Synthesizer architecture was specifically designed in symbiotic harmony with E5’s multilingual capabilities—making it an organic extension rather than a standalone entity. Without their visionary work in advancing multilingual representation, the Tiny Sequence Merger simply would not exist. Their open-source contribution is the true seed from which our innovations grew.
Finesse-Benchmark: Robust Separation Score Benchmark in Python


Introduction
The Finesse Benchmark is a sophisticated evaluation framework designed to assess the performance of long-context embedding models on semantic understanding and information retention. Unlike traditional benchmarks that rely on superficial metrics, Finesse focuses on Relative Semantic Similarity (RSS)—a robust metric that measures how well models distinguish between relevant (“memory”) and irrelevant (“noise”) chunks in long sequences.
Key Features
- Modular Evaluation Modes: Supports
merger_mode(using sequence-merger with a base embedder),native_mode(direct long-context embedders), andBYOK_mode(Bring Your Own Keys for external APIs via LiteLLM) - Dynamic Probe Generation: Creates synthetic probes from atomic text chunks in the dataset, masking portions to test reconstruction accuracy
- Top-Down and Bottom-Up Scoring: Combines contextual coherence with individual chunk integrity
- Reproducibility and Integrity: Outputs include self-contained content hashes for verification
Quick Start
# Install the benchmark
pip install finesse-benchmark
# Initialize configuration
finesse init --output benchmark.yaml
# Generate embeddings (adjust samples as needed)
finesse generate --config benchmark.yaml --output results --samples 5 --seed 42
# Compute scores
finesse score --pt-path results/embeddings_merger_mode_finesse-benchmark-database.pt --output results
# Verify integrity
finesse checksum --json-path results/benchmark_results.json
Available Modes
- Merger Mode: Evaluate sequence-merger models with base embedders
- Native Mode: Test direct long-context embedders like Snowflake Arctic Embed
- BYOK Mode: Use external APIs (OpenAI, Cohere, etc.) via LiteLLM
For detailed configuration options and advanced usage, visit the Finesse-Benchmark GitHub repository or check out the dataset on Hugging Face.
Finess-Benchmark-Leaderboard: Where Performance Meets the True Cost of Context

The FINESSE leaderboard isn’t just a table of numbers—it’s an interactive laboratory for dissecting the profound trade-off between semantic fidelity (how well models capture long-context meaning, measured by RSS/FINESSE scores) and computational efficiency (the real-world ‘price’ of that intelligence, measured by Latency). Here, we reveal the hidden economics of AI embeddings: the ‘true cost of context’ that determines whether a model’s brilliance is practical or prohibitively expensive.
Latency: The True Cost of Context
Latency quantifies the time penalty of processing longer sequences, exposing how architectures scale (or falter) under extended contexts. But our philosophy goes deeper: we measure not just raw speed, but the architectural fairness in revealing efficiency’s roots. Why? Because true innovation lies in decoupling ‘thinking’ from ‘preparation’—caching reusable insights to slash redundant work.
Sequence Merger Models: Efficiency Through Separation (Full Time vs. Merging Only)
For our Sequence Merger architecture, we split Latency into two transparent metrics to highlight its modular genius:
- Full Time: The end-to-end reality of processing a long document from scratch. This includes:
- Chunk Embedding: Time to generate individual embeddings for each segment (e.g., via the base
intfloat/multilingual-e5-basemodel on 512-token chunks). - Merging Only: The core synthesis time—feeding pre-embedded chunks into the Merger for rapid fusion.
- Chunk Embedding: Time to generate individual embeddings for each segment (e.g., via the base
Native Mode Models: The Indivisible Burden of Direct Processing
In stark contrast, Native long-context models (e.g., Snowflake Arctic Embed with 8192 tokens) process the entire sequence in one monolithic pass. There’s no separation of concerns—no caching chunks for reuse. Thus, their time is indivisible:
-
Full Time = Merging Only: A single, exhaustive computation over the full input. Every token demands fresh attention, scaling quadratically with length (O(n²) in Transformers).
Example: For 2048 tokens, it’s one giant forward pass—no shortcuts. This honesty reveals the ‘hidden tax’ of brute-force scaling: impressive RSS scores come at exponentially rising Latency, prohibitive for resource-constrained RAG pipelines.
Philosophical Fairness: We record the same value for both metrics in Native Mode to avoid illusions, a reminder that longer windows demand deeper wallets.
The Leaderboard as Interactive Philosophy
Visit the FINESSE Benchmark Space to explore this trade-off landscape yourself. Toggle between models, sequences (512-8192 tokens), and modes (Merger vs. Native). Watch as our Sarang and Malgeum maintain fair RSS scores with sub-second Latencies—while giants like Arctic Embed trade high RSS score with the latency.
Plus, the Interactive Anatomy Laboratory
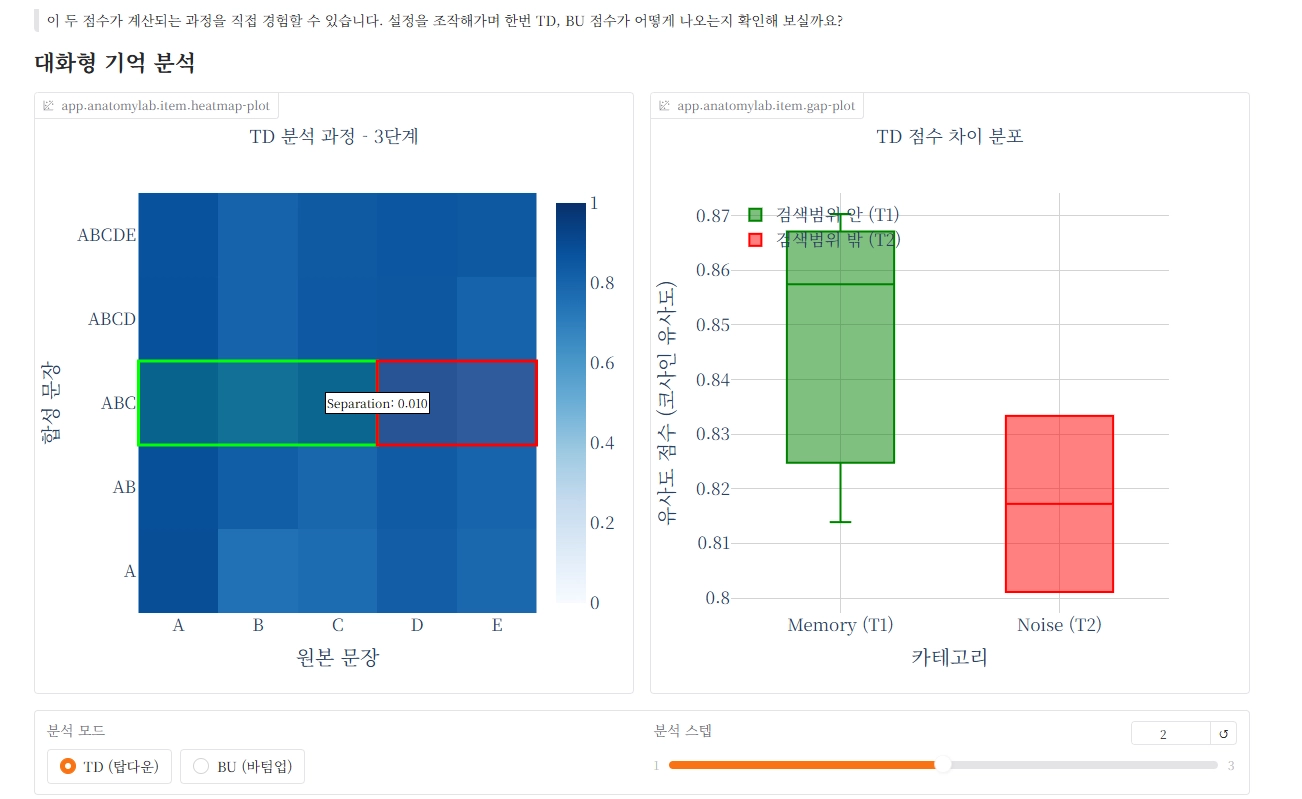
Ready to witness the magic of RSS in action? Dive straight into the Anatomy Laboratory within the FINESSE Benchmark Space. Here, you can experiment with any model, watching as the RSS score unfolds in real-time through TD (Top-Down) and BU (Bottom-Up) analysis. It’s your hands-on portal to understanding how our syntheses preserve—and even enhance—semantic fidelity!
Unceasing Research: Leaving a Mark as an Independent AI/ML Researcher


I’m actively publishing my research and establishing my footprint as an independent AI/ML researcher. While I’m still at the beginning of my journey, I am committed to advancing my work with dedication.
Thank you for reading
This is all I founded. Thank you!
Reference And Citation
[1] 챗GPT, 너의 능력은 어디까지?, 헬스조선
[2] AI Chatbots Are Getting Better. But an Interview With ChatGPT Reveals Their Limits, Times
[3] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Jacob Devlin et al.
[4] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, Patrick Lewis et al.
[5] LongEmbed: Extending Embedding Models for Long Context Retrieval, Dawei Zhu et al.
[6] CAPE: Context-Adaptive Positional Encoding for Length Extrapolation, Chuanyang Zheng et al.
[7] The Impact of Positional Encoding on Length Generalization in Transformers, Amirhossein Kazemnejad et al.
[8] RoBERTa: A Robustly Optimized BERT Pretraining Approach, Yinhan Liu et al.